摘要
随着人工智能在多模态理解方面的进步,视频理解和定位技术在医学教学等专业领域的应用潜力迅速增长。然而,现有基准测试大多集中在英文语料库,并主要关注字幕的检索,限制了对模型深度推理能力的评估。为了解决这些问题,我们提出了M3-Med,这是第一个用于医疗教学视频理解的多语言、多模态、多跳推理基准。该基准由医学专家团队构建,包含一系列医学问题和相应的视频片段作为答案,并创新性地将问题分为简单问题和复杂问题。解决复杂问题需要模型具备构建跨模态知识图谱并进行多跳推理的能力。实验结果表明,M3-Med对现有顶尖模型构成了显著挑战,证明了其作为评估工具的有效性。
数据集获取
点击下方按钮下载完整的数据集。文件为 .zip 格式。由于版权原因,我们不提供视频下载,请根据视频ID使用pytube等工具下载。
下载 M3-Med 数据集 (M3Med.zip)最新动态
- [2025-06-13] 以此数据集衍生的NLPCC 2025 Shared Task 4 发布,详见NLPCC 2025 Shared Task 4 🎉🎉🎉
- [2025-07-07] 我们的论文已在arxiv上发布,详见M3-Med: A Benchmark for Multi-lingual, Multi-modal, and Multi-hop Reasoning in Medical Instructional Video Understanding 🎉🎉🎉
主要特点
多跳推理
引入复杂问题,要求模型进行多跳推理,而不仅仅是文本匹配。
多模态
结合视频视觉信息和文本字幕,评估跨模态理解能力。
多语言
包含中文和英文两种语言,满足全球医学研究的需求。
问题示例
简单问题
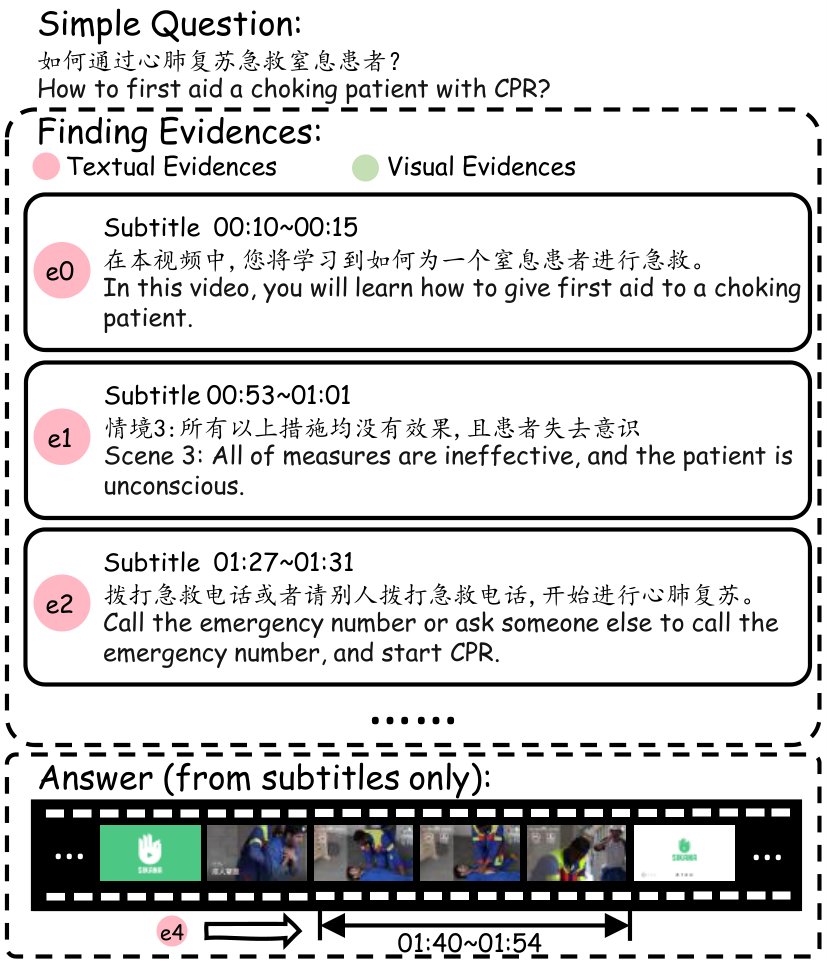
简单问题通常可以直接从视频的某一连续片段中找到答案。
复杂问题
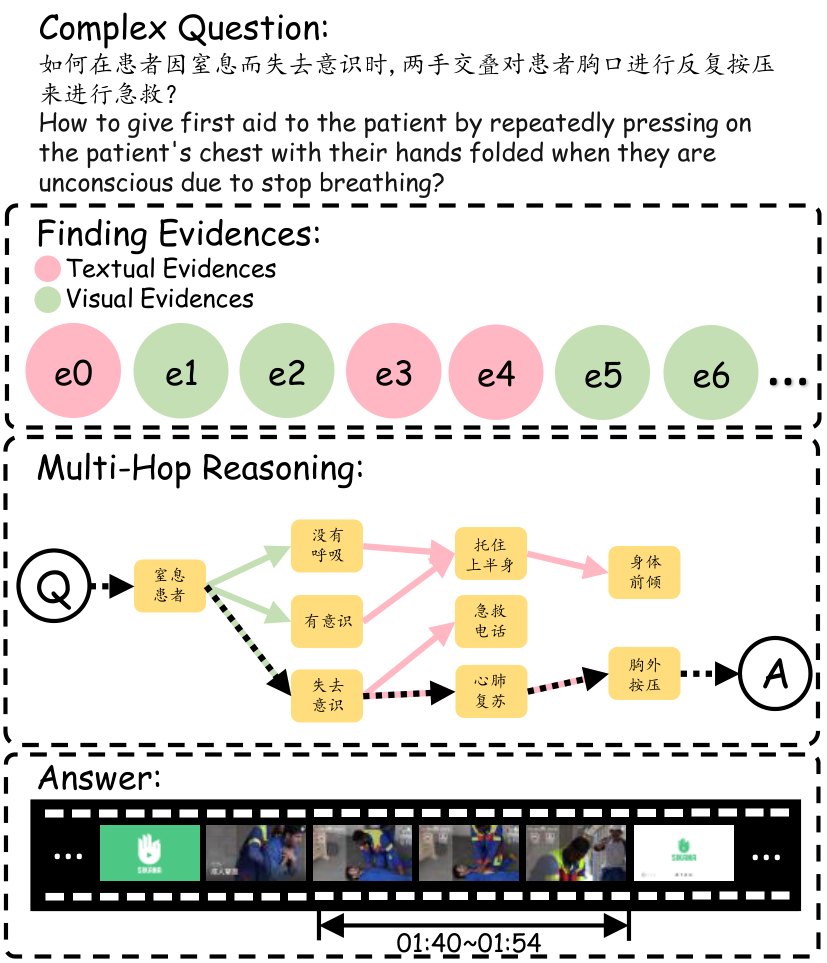
复杂问题则需要模型具备更深层次的理解和推理能力。需要模型整合信息,进行“多跳”推理。
基准构建
- 视频收集: 从YouTube等平台筛选与医学教学高度相关的视频。
- 字幕构建: 使用Whisper模型生成SRT格式的字幕文件。
- 问题编写与审核: 由专业医生编写问题,并经过团队严格审核。
- 时间戳标记与校验: 标记问题对应的答案视频片段,并通过交叉备注和一致性检验确保质量。